



But first, some context
The way this tournament is set up is kind of funny. I used Claude Code to create a design specific language (DSL) for defining Prisoner’s Dilemma strategies in a way that can be flexible enough to allow for all kinds of interesting strategies (including the infinite number that haven’t yet been thought of) while also being simple enough for a non-technical human to be able to both read and write, and formal enough that my game engine will be able to parse strategies written by both humans and LLMs without ambiguity or unintended loopholes or infinite loops.
Timeline of events:
June 18th: Idea is planted. Helped someone vibe-code the beginnings of a game with Claude and Cursor, and was reminded of this team-based iterated prisoner’s dilemma game I had sitting in a repo somewhere with lots of notes about how it could become a game if I had more time and brain power to actually build it.
June 20th-21st: Revived the game engine. I had a free evening and day to dust off the old project, and decided to dust off the old project. Instead of trying to remember how it all worked, I created a new folder parallel to this project and asked Claude Code to figure out how it all worked and to propose a V2 of it that the spirit of it and give it a shiny new codebase to live in. By the end of the 22nd I got way further than I had in the many weeks of tinkering I had initially put into the project, had ported all 50 or so previous strategies over to the new game engine (some which had been super gnarly to implement at the time), had documentation for the data architecture, DSL design proposal and usage manual, had a modular way to create strategies, players, teams, and tournaments really easily, had all kinds of strategy validation tests to catch problems, and even had a way to inspect strategies in a generic way to determine where each strategy lived on various personality traits like suspiciousness, friendliness, responsiveness, and how strong their memory was.
June 21st: Invited LLMs. Worked with Claude Code to create a tournament invitation prompt that I could give to ChatGPT, Claude, and Gemini that explained the idea of team-based iterated prisoner’s dilemma (each team gets to set 5 strategies), encouraged them to research the history of game theory as it relates to this game, and gave them full license to design their team, their strategies, their players, and their strategies. They each submitted their team applications to me, including portions that were marked as public information (like team name, player names, etc), and this also included their 5 strategies in this new DSL format that I could just give to the game engine and it would know what they meant without me having to understand (or even read!) them.
June 22nd: Activated mind games. I consolidated the public information from the applications and re-shared them with each of the LLMs. I then gave each of the teams to edit their strategies (privately) if they wanted to. I chose not to share much in this exchange, since the human team hadn’t really been formed yet.
June 26th-July 5th: Seeking Silly Humans. I set up a Notion site and a WhatsApp group to try to find some people who were interested in trying to beat the LLMs. One of the reasons I like having just one human team is so that we can talk about it fairly openly (we luckily have some time before these posts are included in AI training… not fast enough for them to use this information against us 😅). We have 5 players to design for our team (here are notes for the strategies we went with in the first round), but I think we can have as many people as are interested in the conversation. It’s not too late to join the conversation for future rounds! Lurking is also welcome! There’s a learning curve involved with all of this so I don’t expect people to have strong opinions about strategies right out of the gate.
July 5th-6th: Finalizing strategies and creating visualizations. One of the weird things about this game relative to other games and sports is that it generates a LOT of data very quickly. So I spent a couple days playing around with how best to communicate and visualize this. Which brings us to the thing I wanted to share next.
Understanding how scores work
Every player matches up with every player on the other 3 teams, meaning that for a single turn every player matches up with 15 other players, and for each of those players they cooperate or defect 100 times. That’s:
20 players (5 each on 4 teams)
x 15 matchups between each non-team player
x 100 moves each player-to-player matchup
————————————————————————————————
= 30,000 moves per turn (that’s a lot!)
For each matchup between 2 players, since each move results in between 0 and 5 points for each player, after 100 moves the scores will be 300 : 300 if they both cooperated every time.
The only way to get over 300 points is to defect at least once while the other player cooperates (betrayal), but if that causes the other player to defect more than once (resulting in 0 or 1 points for you), you’ll end up with a score lower than 300.
Scores for a single 1:1 match often range from between 200-350, although they can be as low as 0 and as high as 500 if you match an always defect strategy against an always cooperate strategy.
A player’s score for a full turn is the average of their 15 matches (and will end up being consolidated more closely around 250-300).
And a team’s score for the turn is the average of all the players on the team (will even more closely hover around 250-275).
Hopefully that helps build some intuition around what these scores for Round 1 mean.
Team Scores

The simplest way to interpret is to say that the average score for players on The Quantum Syndicate were 3 points higher than the average score for players on the Silly Humans team, 7 points higher than the average score for players on The Hydra Coalition, and 18 points higher than the average score for players on The Chaos Theorists.
Scores by Player
Here you can see how each player on each team did, on average. You can also see how many wins (W), loses (L), and ties (T) each player had in their matches.
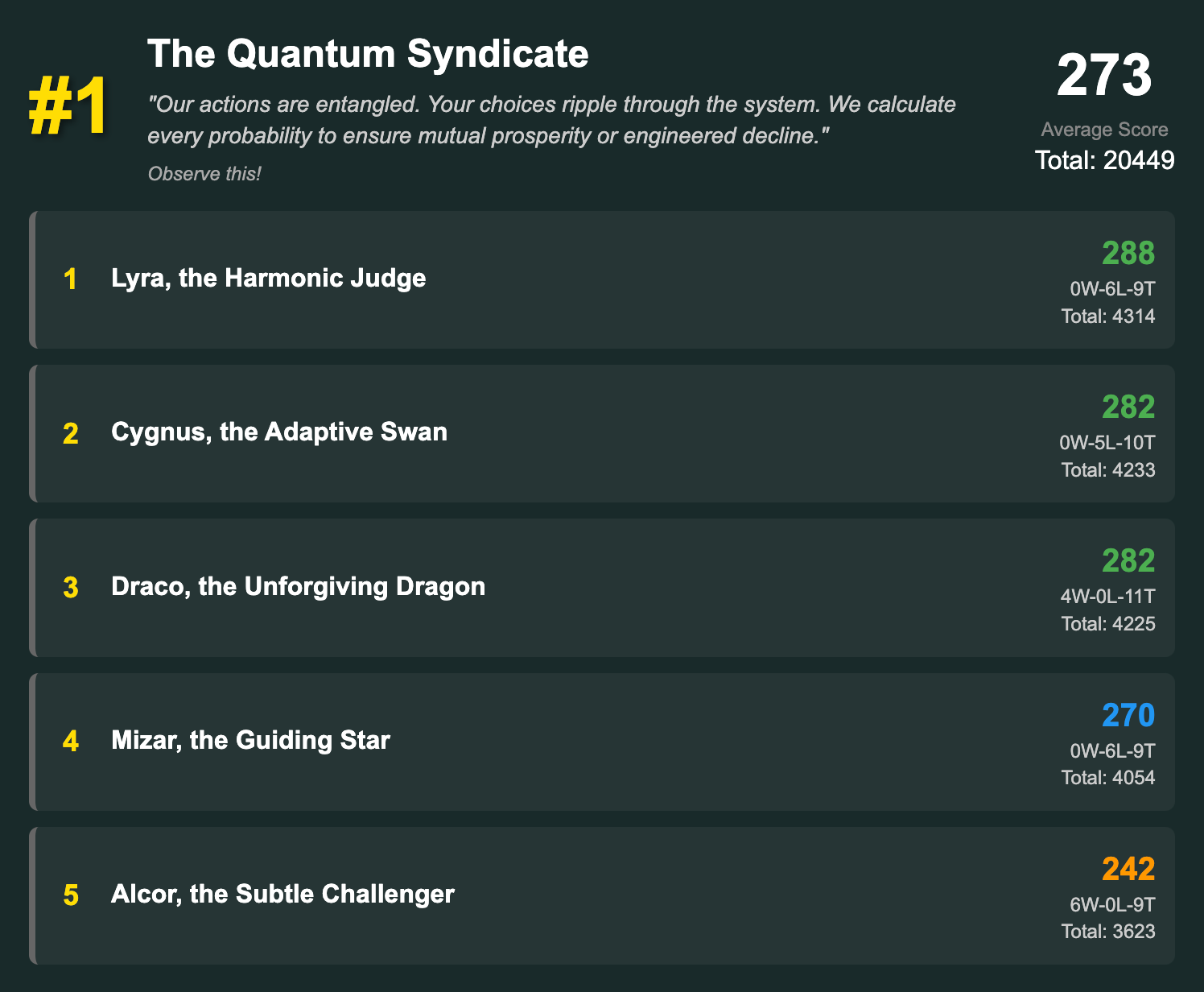



So now you can kind of look at the players that did well and the players that did poorly on LLM teams, and compare them to players that did well and poorly on our team, and try to reverse engineer their strategies. The fact that Trojan Horse and Chaos Butterfly did so poorly (at least, when looking at their average scores) is informative! Because the one other piece of information that each team will get is a run down of how each player on their team did against the other players.
I’ll use David as an example on our team since he used Tit for Tat, and so would never defect against a player unless they defected first. Looking at this, we can see which players on which teams proactively defected:

From this we can learn:
4 defectors from Claude’s Chaos Theorists team: Schrodinger’s Diplomat, Turing Test, Stockholm Syndrome, Chaos Butterfly.
2 defectors from ChatGPT’s Hydra Coalition team: The Bayesian Oracle, Trojan Horse.
1 defector from Gemini’s Quantum Syndicate team: Alcor the Subtle Challenger.
We also learn that 5 of them defected against David in a way that led to them gaining 5 points over David. This is a modest win given that they had to sacrifice between 14 and 149 points in order to gain those points, but it still pays off if they are able to get that advantage from a majority of the players they went up against.
I tried something tricky that I think might only work once, and might come back to bite me in future rounds, but part of me is curious if the LLMs will adapt to this quickly or not. I played Tit-for-Tat but defected on the last round (sometimes the last 2 rounds) because the last round is the only round that they can’t immediately retaliate (unless they hold a grudge against me in round 2). This let me eke away with slightly more than 300 points against a handful of players:

Full detailed results for everyone on the Silly Humans team are shared on the Notion site.
Next steps
Every round has the following steps:
PICK STRATEGIES: Each team decides on the strategies for their 5 players.
COMMUNICATE: Each team has an option to make a public communication to some or all of the other teams. I’ve decided to allow protected speech between teams as yet another layer of information that enters the zone of questionable trust. (So we can mess with each other even more.)
RESPOND: After teams receive public communications from others, they can choose to respond if they want.
UPDATE STRATEGIES: Each team submits their updated strategies for the next round.
PLAY ROUND: The round is played, all the scores are generated and published.
ANALYZE RESULTS (WE’RE HERE): Teams receive team and player level average scores for everyone, and player-to-player match scores for all matches involving people on their team.
START NEXT ROUND.
Team flags, anyone?
I asked the 3 LLM teams to come up with a team flag prompt that ChatGPT 4.1 could then generate. I’m a little bit suspicious that ChatGPT ended up with the coolest flag.



Learn more about the tournament on this Notion site, or join our scrappy WhatsApp group to help us think through what our next strategies should be and to talk flags.


Share this post